1. 알고리즘의 선택
1) 합병 정렬(merge sort)
- 분할, 정복, 결합 이라는 3가지 단계를 통해 정렬이 이루어 진다.
- 분할: 입력 배열을 같은 크기의 2개의 부분 배열로 분할한다.
- 정복: 부분 배열을 정렬한다. 만약 충분히 작지 않으면 순환호출을 통해서 분할 -> 정복의 과정을 수행한다.
- 결합: 정렬된 부분 배열들을 하나의 배열로 합병한다. 합병하는 과정에서 실제로 정렬이 일어나게 된다.
- 아래의 이미지를 통해 실제로 동작하는 방식을 머리속에 그려 볼 수 있다.

출처: https://gmlwjd9405.github.io/images/algorithm-merge-sort/merge-sort-concepts.png
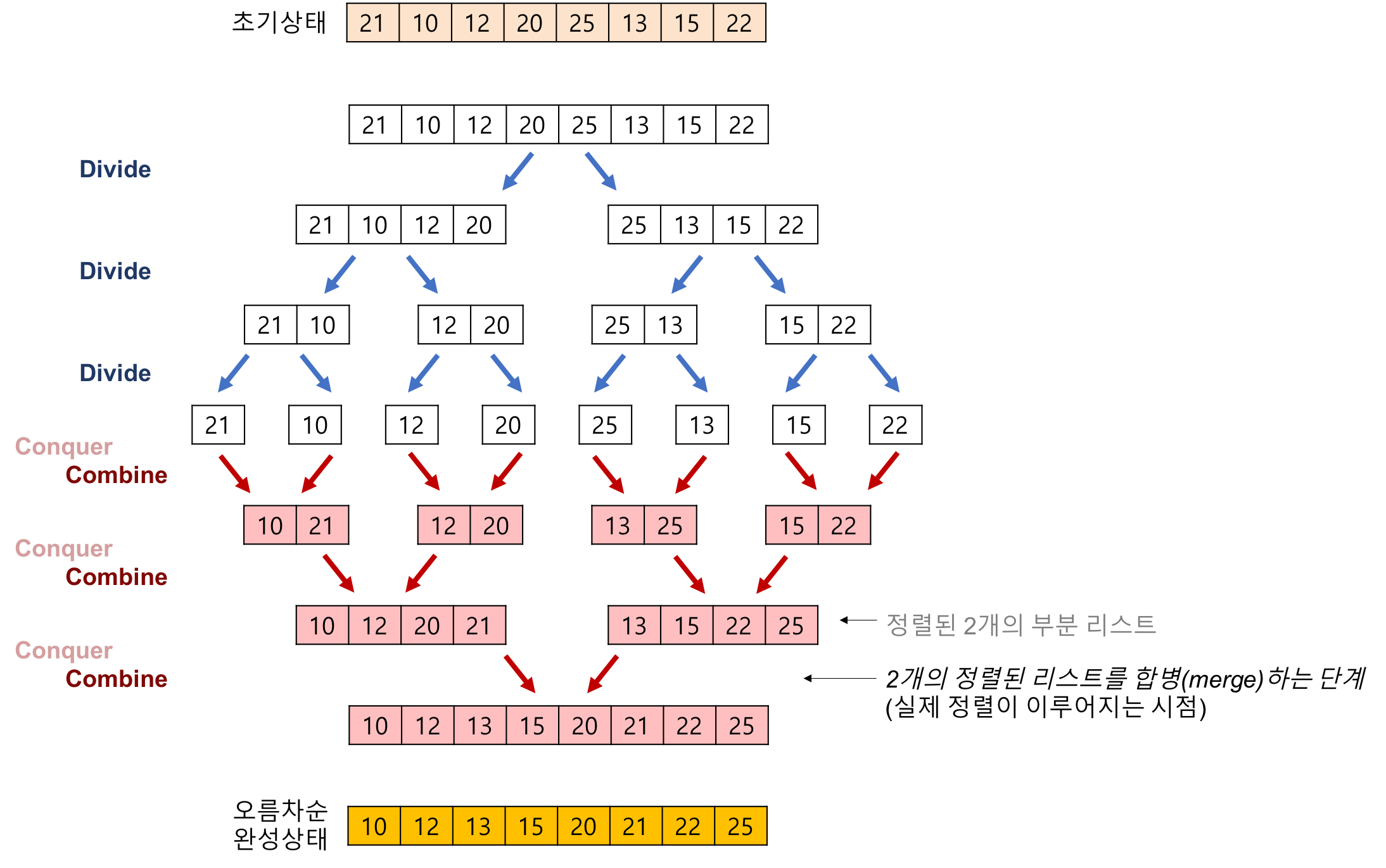{kind=link}
- 컴바인 과정 살펴보기
- 위와 같은 Divide 과정을 거쳐 우리는 2개의 정렬된 리스트를 얻게 되었다.
- 하나의 리스트로 이를 정렬하는 과정에서 각 리스트의 요소들을 하나씩 비교하면 더 작은 수를 앞쪽에 배치하는 과정을 통해 정렬을 진행한다.

출처: https://gmlwjd9405.github.io/images/algorithm-merge-sort/merge-sort.png
2) 합병 정렬의 장단점
(1) 장점
- 원본 배열을 절반으로 나누어 정렬을 한다는 점에서 퀵소트와 유사하나 pivot 설정 없이 항상 두개로 분할하기 때문에 O(N x logN)이라는 시간 복잡도가 보장된다.
(2) 단점
- 공간 복잡도가 증가한다. 즉, 임시배열에 원본맵을 계속해서 옮겨주며 정렬을 하는 방식이기 때문에 추가적인 메모리가 필요하다.
- 추가적인 메모리를 할당할 수 없다면 퀵소트를 사용한다.
2. 자료 구조 선택
1) 이중 연결 리스트
(1) 장점
- 조회하는 데이터의 인덱스에 따라 앞 || 뒤에서 검색이 가능함으로 검색의 효율을 높일 수 있다.
- 즉, 이중연결리스트의 element 수의 중앙값을 기준으로 요구하는 인덱스의 값이 크거나 작을 때 next 또는 previous를 이용해 효율적으로 찾을 수 있다.
(2) 단점
- previous라는 필드를 유지해야 하기 때문에 메모리를 더 많이 사용한다.
- 조금 더 복잡(?) -_-;;
참고자료
- 분할 정복 알고리즘의 하나(https://gmlwjd9405.github.io/2018/05/08/algorithm-merge-sort.html)
- 샐활코딩 이중 연결 리스트 (https://opentutorials.org/module/1335/8940)
'Push_Swap' 카테고리의 다른 글
| [Day1 - Push_Swap]Research - Big O (0) | 2021.06.27 |
|---|